카이스트 연구진, ‘상보형-트랜스포머’ 구현
"초저전력·고성능 온디바이스 AI 가능하다는 것 입증"
[포쓰저널=이현민 기자] 인간 뇌의 동작을 모사하는 뉴로모픽 컴퓨팅 기술을 이용해 거대언어모델(LLM)을 순식간에 처리할 수 있는 인공지능(AI) 반도체가 국내 연구진에 의해 탄생했다.
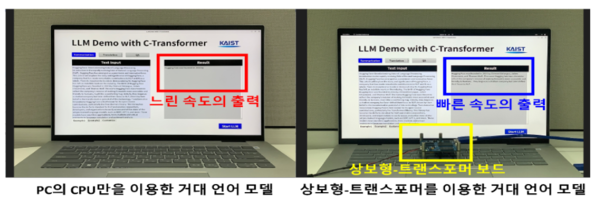
6일 과학기술정보통신부에 따르면 400mW 초저전력을 소모하면서 0.4초 초고속으로 거대 언어 모델을 처리할 수 있는 AI 반도체인 ‘상보형-트랜스포머(Complementary-Transformer)’가 삼성전자 28나노(nm) 공정을 통해 세계 최초로 개발됐다.
해당 반도체는 카이스트(KAIST) PIM반도체 연구센터, AI 반도체 대학원 유회준 교수 연구팀이 공동으로 개발했다.
과기부에 따르면 연구팀은 그동안 다량의 GPU(그래픽 처리장치)와 250W의 전력소모를 통해 구동되는 GPT 등 거대 언어 모델을 4.5㎜x4.5㎜의 작은 한 개의 AI 반도체 칩 상에서 초저전력으로 구현하는 것에 성공했다.
특히 인간 뇌의 동작을 모사하는 뉴로모픽 컴퓨팅 기술, 즉 스파이킹 뉴럴 네트워크(Spiking Neutral Network, SNN)을 활용해 트랜스포머 동작을 구현한 것이 특징이다.
김상엽 박사가 제 1저자로 참여한 이번 연구는 2월 19일부터 23일까지 미 샌프란시스코에서 개최된 국제고체회로설계학회(ISSCC)에서 발표 및 시연됐다.
기존 뉴로모픽 컴퓨팅 기술은 합성곱신경망(Convolutional Neural Network, CNN)에 비해 부정확하며 주로 간단한 이미지 분류 작업만 가능했다.
연구팀은 뉴로모픽 컴퓨팅 기술의 정확도를 합성곱신경망과 동일 수준으로 끌어올리고 단순 이미지 분류를 넘어 다양한 응용 분야에 적용할 수 있는 상보형-심층신경망을 제안했다.
상보형 심층신경망 기술은 지난해 2월에 개최된 국제고체회로설계학회(ISSCC)에서 김상엽 박사가 발표했다.
심층 인공 신경망(Deep Neural Network, DNN)과 스파이킹 뉴럴 네트워크를 혼합해 사용하며 입력 데이터들을 크기에 따라 서로 다른 신경망에 할당해 전력을 최소화할 수 있는 기술이다.
사람의 뇌가 생각할 것이 많을 때 에너지 소모가 많고 생각할 것이 적을 때 에너지 소모가 적은 것과 마찬가지로 뇌를 모방한 스파이킹 뉴럴 네트워크는 입력값의 크기가 클 때는 전력을 많이 소모하고 입력값의 크기가 작을 때에는 전력을 적게 소모한다.
지난해 연구에서는 이러한 특징을 활용해 작은 입력값들만을 스파이킹 뉴럴 네트워크에 할당하고 큰 값들은 심층 인공 신경망에 할당해 전력 소모를 최소화했다.
이번 연구는 지난해의 상보형-심층신경망 기술을 거대 언어 모델에 적용함으로써 초저전력·고성능의 온디바이스 AI가 가능하다는 것을 실제로 입증한 것이며 그동안 이론적인 연구에만 머물렀던 연구내용을 세계 최초로 인공지능 반도체 형태로 구현한 것에 의의가 있다는 것이 과기부의 설명이다.
특히 연구팀은 뉴로모픽 컴퓨팅의 실용적인 확장 가능성에 중점을 두고 문장 생성, 번역, 요약 등과 같은 고도의 언어 처리 작업을 성공적으로 수행할 수 있는지를 연구했다.
그 과정에서 가장 큰 관건은 뉴로모픽 네트워크에서 높은 정확도를 달성하는 것이었다.
일반적으로 뉴로모픽 시스템은 에너지 효율은 높지만 학습 알고리즘의 한계로 인해 복잡한 작업을 수행할 때 정확도가 떨어지는 경향이 있었으며 거대 언어 모델과 같이 높은 정밀도와 성능이 요구되는 작업에서 큰 장애 요소로 작용했다.
이러한 문제를 해결하기 위해 연구팀은 독창적인 DNN-to-SNN 등가변환기법을 개발해 적용했다. 이는 기존의 심층 인공 신경망 구조를 스파이킹 뉴럴 네트워크로 변환하는 방법의 정확도를 더욱 끌어올리기 위해 스파이크의 발생 문턱값을 정밀 제어하는 방법이다.
이를 통해 연구팀은 스파이킹 뉴럴 네트워크의 에너지 효율성을 유지하면서도 심층 인공 신경망 수준의 정확도를 달성할 수 있었다.
이번 연구를 통해 개발한 인공지능반도체용 하드웨어 유닛은 기존 거대 언어 모델 반도체 및 뉴로모픽 컴퓨팅 반도체에 비해 4가지의 특징을 지닌다.
심층 인공 신경망과 스파이킹 뉴럴 네트워크를 상호 보완하는 방식으로 융합한 독특한 신경망 아키텍처를 사용함으로써 정확도를 유지하면서도 연산 에너지 소모량을 최적화했으며 심층 인공 신경망과 스파이킹 뉴럴 네트워크를 상보적으로 활용해 모두 효율적으로 신경망 연산을 처리할 수 있는 인공지능반도체용 통합 코어 구조를 개발했다.
스파이킹 뉴럴 네트워크 처리에 소모되는 전력을 줄이기 위해 출력 스파이크 추측 유닛을 개발하였으며 거대 언어 모델의 파라미터를 효과적으로 압축하기 위해 빅-리틀 네트워크(Big-Little Network) 구조와 암시적 가중치 생성기법, 부호압축까지 총 3가지 기법을 사용했다.
GPT-2 거대(Large) 모델의 708M개에 달하는 파라미터를 191M개로 줄였으며 번역을 위해 사용되는 T5 (Text–to-Text Transfer Transformer)모델의 402M개에 달하는 파라미터 역시 동일한 방식을 통해 76M개로 줄일 수 있었다.
이러한 압축을 통해 연구진은 언어 모델의 파라미터를 외부 메모리로부터 불러오는 작업에 소모되는 전력을 약 70% 감소시키는 것에 성공했다.
상보형-트랜스포머는 전력 소모를 GPU(NVIDIA A100) 대비 625배만큼 줄이면서도 GPT-2 모델을 활용한 언어 생성에는 0.4초의 고속 동작이 가능하며 T5 모델을 활용한 언어 번역에는 0.2초의 고속 동작이 가능하다는 것이 과기부의 설명이다.
파라미터 압축에 따른 정확도 하락을 방지하기 위해 경량화 정도에 따른 정확도 하락률을 반복 측정해 최적화했다.
이러한 특징을 바탕으로 연구팀은 이번 연구 성과는 모바일 장치 등 에너지 제약이 높은 환경에서도 정확하게 거대 언어모델을 구동할 수 있어 온디바이스AI 구현을 위한 최적의 기술이라고 밝혔다.
연구팀은 향후 뉴로모픽 컴퓨팅을 언어 모델에 국한하지 않고 다양한 응용 분야로 연구범위를 확장할 것이며 상용화에 관련된 문제점들도 파악하여 개선할 예정이라고 밝혔다.
KAIST 유회준 전기및전자공학부 교수는 “이번 연구는 기존 인공지능반도체가 가지고 있던 전력 소모 문제를 해소했을 뿐만 아니라 GPT-2와 같은 실제 거대언어모델 응용을 성공적으로 구동했다는데 큰 의의가 있다”며 “뉴로모픽 컴퓨팅은 인공지능시대에 필수적인 초저전력·고성능 온디바이스AI의 핵심기술인만큼 앞으로도 관련 연구를 지속할 것”이라고 했다.
전영수 과기부 정보통신산업정책관은 “이번 연구성과는 인공지능반도체가 NPU(신경망처리장치)와 PIM을 넘어 뉴로모픽 컴퓨팅으로 발전할 수 있는 가능성을 실제로 확인했다는 것에 큰 의미가 있다”며 “1월 대통령 주재 반도체 민생토론회에서 AI반도체의 중요성이 강조됐듯이 앞으로도 이러한 세계적인 연구성과를 지속적으로 낼 수 있도록 적극적으로 지원하겠다”고 했다.